定义
- 模块:用来从逻辑上组织python代码(变量、函数、类等),本质是.py结尾的python文件。例:文件名:test.py;模块名:test。
- 包:用来从逻辑上组织模块,本质是一个带有
__init__.py文件的目录
使用方法
- import module_name1, module_name2
- import module_name as mod
- from module_name import m1, m2, m3, …
- from module_name import *
- from module_name import func as f
- from . import module_name # (其中 . 指当前路径)
import本质
- 导入模块的本质就是把对应Python文件解释一遍
- 导入包的本质就是执行该包下的__init__.py文件
路径搜索
import导入模块时,是按照sys.path列表包含的路径执行的,其第一个元素就是当前文件目录,其他元素为python标准库及第三方库的路径。若要跨路径导入模块,方法如下:
import os
import sys
__file__ # 当前文件的相对路径
os.path.abspath(__file__) # 当前文件的绝对路径
os.path.dirname(os.path.abspath(__file__)) # 当前文件的上一级目录
# 当前文件的上上级目录
DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(DIR) # 添加环境变量
导入优化
若多次用到某模块的单一功能,导入模块时用:
# import module_name
from module_name import func
这样可以节省多次搜索路径的时间。
模块的分类
- 标准库
- 开源模块
- 自定义模块
常用标准库模块
- time 和 datetime
时间的表示方法:格式化字符串 Format string、时间戳 Timestamp、结构化元组 struct_time。
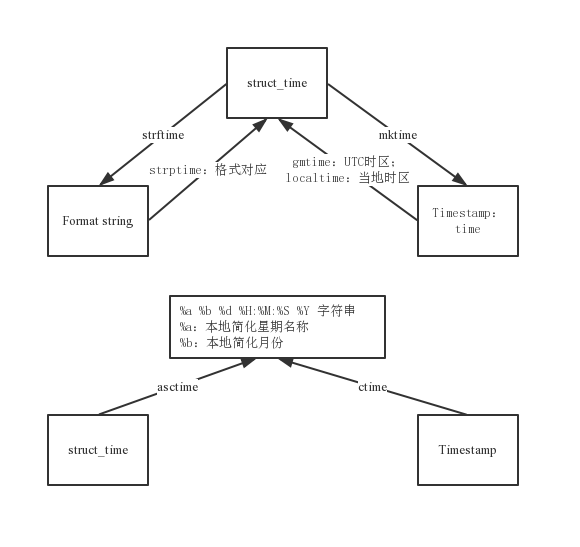
时间加减:
import time
import datetime
print(datetime.datetime.now()) # 返回 2019-02-19 13:12:26.941925
print(datetime.date.fromtimestamp(time.time())) # 时间戳转日期格式 2019-02-19
print(datetime.datetime.now() + datetime.timedelta(3)) # 当前时间+3天
print(datetime.datetime.now() + datetime.timedelta(-3)) # 当前时间-3天
print(datetime.datetime.now() + datetime.timedelta(hours=3)) # 当前时间+3小时
print(datetime.datetime.now() + datetime.timedelta(minutes=30)) # 当前时间+30分钟
print(datetime.datetime.now().replace(minute=30, hour=5)) # 时间替换
- random
import random
print(random.random()) # [0, 1.0]随机浮点数
print(random.uniform(1, 5)) # [1, 5.0]随机浮点数
print(random.randint(10, 50)) # [10, 50]随机整数
print(random.randrange(5)) # 从range(5)中随机取出
print(random.choice(sequence)) # 从字符串或列表、元组等有序类型中随机取出一个元素
print(random.sample(sequence, k)) # 从有序类型中随机取出k个元素
# 洗牌
item = [1,2,3,4]
random.shuffle(item)
print(item)
# 生成验证码
checkcode = ''
for i in range(4):
num = random.randrange(48, 58)
char = random.randrange(65, 91)
if random.randint(0, 1):
checkcode+=chr(num)
else:
checkcode+=chr(char)
print(checkcode)
- os
import os
print(os.getcwd()) # 获取当前工作目录,不含文件
os.chdir(path) # 相当于shell下的cd。要两个斜杠'c:\\Users',或者r'c:\Users'
os.curdir # 返回当前目录
os.pardir # 返回上级目录
os.makedirs(r'e:\a\b\c\d') # 创建多级递归目录
os.removedirs(r'e:\a\b\c\d') # 递归删除多级空目录
os.mkdir(r'e:\a') # 创建单级目录
os.rmdir(r'e:\a') # 删除单级空目录
print(os.listdir(r'e:\aaa')) # 列出路径下的文件和子目录,包括隐藏
os.remove() # 删除一个文件
os.rename() # 重命名文件
os.stat() # 获取文件或目录信息
print(os.sep) # 路径分隔符:Windows'\',Linux'/'
print(os.linesep) # 行终止符:Windows'\r\n',Linux'\n'
print(os.pathsep) # 分割文件路径的字符串:Windows';',Linux':'
print(os.name) # 当前使用平台:Windows'nt',Linux'posix'
os.system('ipconfig') # 运行shell命令,直接显示
print(os.environ) # 获取系统环境变量
os.path.abspath() # 获取路径的绝对路径
os.path.split() # 将路径分割为目录和文件返回二元组
os.path.dirname() # 返回值为上级目录
os.path.basename() # 返回最后一级文件夹名或文件名
os.path.exists() # 判断路径是否存在
os.path.isabs() # 判断路径是否绝对路径
os.path.isfile() # 判断是否是文件
os.path.isdir() # 判断是否是目录
print(os.path.join(r'e:\aaa','a','b','c.txt')) # 将多个路径合并返回
os.path.getatime() # 返回最后存取时间
os.path.getctime() # 返回最后修改时间
- sys
import sys
sys.argv # 命令行参数列表,第一个元素是程序本身路径
sys.exit(n) # 退出程序,正常退出时exit(0)
print(sys.version) # python解释器版本
print(sys.platform) # 操作系统平台名称
print(sys.path) # 返回模块的搜索路径
sys.stdout.write('please:') # 标准输出
sys.stdin.readline() # 标准输入
- shutil
import shutil
shutil.copyfileobj(f1, f2) # 把f1复制到f2,f1和f2为文件句柄
shutil.copyfile('filename1', 'filename2') # 复制文件
shutil.copymode() # 复制权限
shutil.copystat() # 复制状态信息
shutil.copytree() # 递归复制目录
shutil.rmtree() # 递归删除目录
shutil.move() # 递归移动文件
shutil.make_archive() # 压缩文件或目录,用了zipfile和tarfile模块
- json和pickle
import json
# json序列化,不同语言可以通用,只能处理简单数据类型
with open('dic', 'w', encoding='utf-8') as f:
data = {
'name': 'zzk',
'age': '23'
}
f.write(json.dumps(data))
with open('dic', 'r', encoding='utf-8') as f:
data = json.loads(f.read())
print(data['name'])
import pickle
# pickle序列化,只用于python
with open('dic', 'wb') as f:
def foo():
print('a')
data = {
'name': 'zzk',
'age': '23',
'func': foo
}
# f.write(pickle.dumps(data))
pickle.dump(data,f)
with open('dic', 'rb') as f:
# data = pickle.loads(f.read())
data = pickle.load(f)
data['func']()
- shelve
import shelve
# shelve模块是一个可以将内存数据通过文件持久化的模块,支持pickle可支持的python数据格式
d = shelve.open('file_name') # 打开一个文件
# info_dict = {'age': 23,'job': 'IT'}
# name_list = ['a', 'b', 'c']
# def foo_func():
# return 'in the foo'
# d['name'] = name_list # 持久化列表
# d['info'] = info_dict # 持久化字典
# d['foo'] = foo_func() # 持久化函数
# d.close()
print(d.get('name'))
print(d.get('info'))
print(d.get('foo'))
d.close()
- configparser
import configparser
# 写入配置文件
config = configparser.ConfigParser()
config['DEFAULT'] = {'a': 1, 'b': 2, 'c': 3}
config['bitbucket.org'] = {}
config['bitbucket.org']['User'] = 'hg'
config['topsecret.server.com'] = {}
secret = config['topsecret.server.com']
secret['ddd'] = '444'
with open('example.ini', 'w') as configfile:
config.write(configfile)
# 解析配置文件
config.read('example.ini')
print(config.defaults())
print(config.sections())
print(config['bitbucket.org']['User'])
- re
- ’.’:匹配任意一个字符,除了\n
- ’^’:匹配开头字符
- ’$’:匹配结尾字符
- ‘*‘:*前的字符匹配0个或多个
- ’+’:+前的字符匹配1个或多个
- ’?’:?前的字符匹配0个或1个
- ‘{m}’:前一个字符匹配m个
- ‘{n,m}’:前一个字符匹配n到m个
-
’ ‘:匹配 前或后的字符 - ’()’:分组匹配
- ‘\A’:同^
- ‘\Z’:同$
- ‘\d’:匹配数字
- ‘\D’:匹配非数字
- ‘\w’:匹配[A-Za-z0-9]
- ‘\W’:匹配非[A-Za-z0-9]
- ’[]’:匹配符合[]内的字符
- ’s’:匹配空白字符\t, \n, \r
# (?P\<name>...) a = re.search('(?P<area>[0-9]{6})(?P<birthyear>[0-9]{4})(?P<birthday>[0-9]{4})',\ '310000197001011024').groupdict() print(a, a['birthyear'])
re.match() # 匹配字符串开头
re.search() # 全字符串搜索
re.findall() # 符合条件的全部返回
re.split() # 按条件分割返回列表
re.sub() # 替换